Question
In: Computer Science
1. List and briefly describe the types of Parallel Computer Memory Architectures. What type is used...
1. List and briefly describe the types of Parallel Computer Memory Architectures. What type is used by OpenMP and why?
2. What is Parallel Programming?
Solutions
Expert Solution
Answer:-
1)List and briefly describe the types of Parallel Computer Memory Architectures. What type is used by OpenMP and why?
ans:-
Uniform Memory Access (UMA)
In this model, all the processors share the physical memory uniformly. All the processors have equal access time to all the memory words. Each processor may have a private cache memory. Same rule is followed for peripheral devices.
When all the processors have equal access to all the peripheral devices, the system is called a symmetric multiprocessor. When only one or a few processors can access the peripheral devices, the system is called an asymmetric multiprocessor.
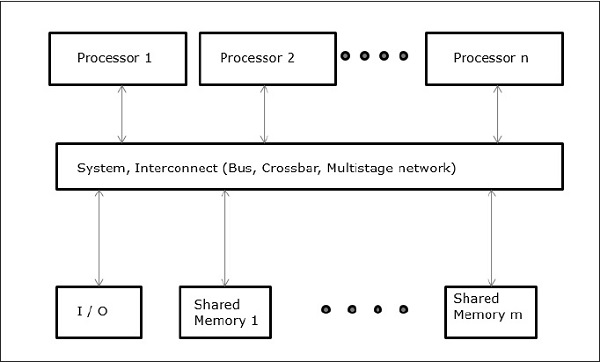
Non-uniform Memory Access (NUMA)
In NUMA multiprocessor model, the access time varies with the location of the memory word. Here, the shared memory is physically distributed among all the processors, called local memories. The collection of all local memories forms a global address space which can be accessed by all the processors.
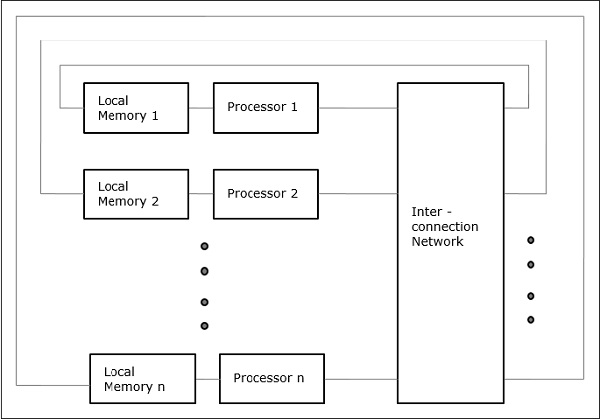
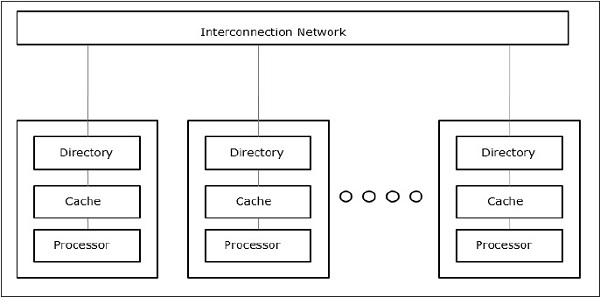
Cache Only Memory Architecture (COMA)
The COMA model is a special case of the NUMA model. Here, all the distributed main memories are converted to cache memories.
-
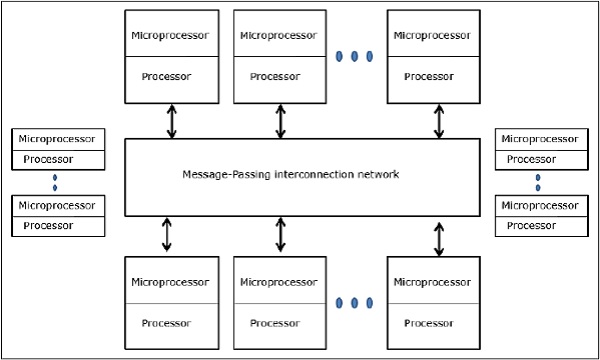
Distributed - Memory Multicomputers − A distributed memory multicomputer system consists of multiple computers, known as nodes, inter-connected by message passing network. Each node acts as an autonomous computer having a processor, a local memory and sometimes I/O devices. In this case, all local memories are private and are accessible only to the local processors. This is why, the traditional machines are called no-remote-memory-access (NORMA) machines.
Multivector and SIMD Computers
In this section, we will discuss supercomputers and parallel processors for vector processing and data parallelism.
Vector Supercomputers
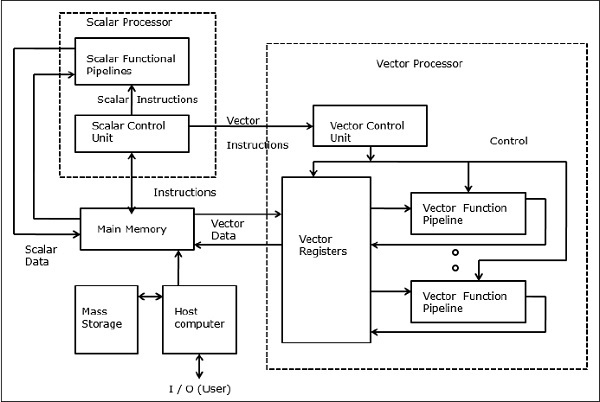
In a vector computer, a vector processor is attached to the scalar processor as an optional feature. The host computer first loads program and data to the main memory. Then the scalar control unit decodes all the instructions. If the decoded instructions are scalar operations or program operations, the scalar processor executes those operations using scalar functional pipelines.
On the other hand, if the decoded instructions are vector operations then the instructions will be sent to vector control unit.
SIMD Supercomputers
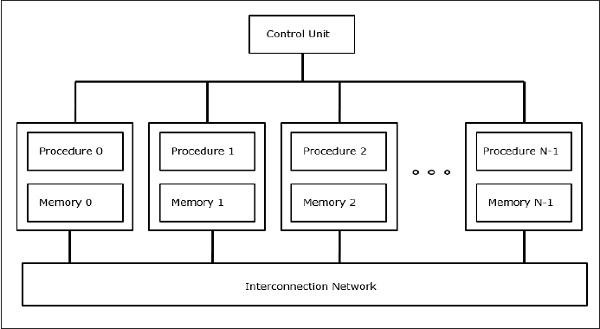
In SIMD computers, ‘N’ number of processors are connected to a control unit and all the processors have their individual memory units. All the processors are connected by an interconnection network.
PRAM and VLSI Models
The ideal model gives a suitable framework for developing parallel algorithms without considering the physical constraints or implementation details.
The models can be enforced to obtain theoretical performance bounds on parallel computers or to evaluate VLSI complexity on chip area and operational time before the chip is fabricated.
Parallel Random-Access Machines
Sheperdson and Sturgis (1963) modeled the conventional Uniprocessor computers as random-access-machines (RAM). Fortune and Wyllie (1978) developed a parallel random-access-machine (PRAM) model for modeling an idealized parallel computer with zero memory access overhead and synchronization.
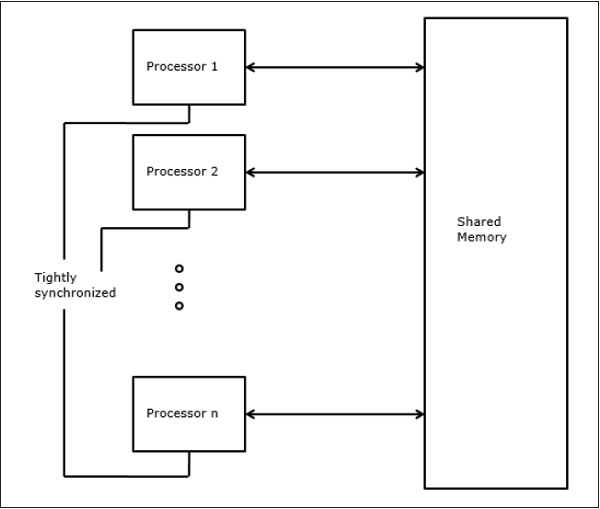
An N-processor PRAM has a shared memory unit. This shared memory can be centralized or distributed among the processors. These processors operate on a synchronized read-memory, write-memory and compute cycle. So, these models specify how concurrent read and write operations are handled.
Following are the possible memory update operations −
-
Exclusive read (ER) − In this method, in each cycle only one processor is allowed to read from any memory location.
-
Exclusive write (EW) − In this method, at least one processor is allowed to write into a memory location at a time.
-
Concurrent read (CR) − It allows multiple processors to read the same information from the same memory location in the same cycle.
-
Concurrent write (CW) − It allows simultaneous write operations to the same memory location. To avoid write conflict some policies are set up
. What type is used by OpenMP and why?
Uniform Memory Access (UMA)
In this model, all the processors share the physical memory uniformly. All the processors have equal access time to all the memory words. Each processor may have a private cache memory. Same rule is followed for peripheral devices.
why
In UMA, where Single memory controller is used. Uniform Memory Access is slower than non-uniform Memory Access. In Uniform Memory Access, bandwidth is restricted or limited rather than non-uniform memory access.
2)
In very simple terms, it is the use of multiple resources, in this case, processors, to solve a problem. This type of programming takes a problem, breaks it down into a series of smaller steps, delivers instructions, and processors execute the solutions at the same time. It is also a form of programming that offers the same results as concurrent programming but in less time and with more efficiency. Many computers, such as laptops and personal desktops, use this programming in their hardware to ensure that tasks are quickly completed in the background.
Advantages
There are two major advantages to using this programming over concurrent programming. One is that all processes are sped up when using parallel structures, increasing both the efficiency and resources used in order to achieve quick results. Another benefit is that parallel computing is more cost efficient than concurrent programming simply because it takes less time to get the same results. This is incredibly important, as parallel processes are necessary for accumulating massive amounts of data into data sets that can be easy to process or for solving complicated problems.
Disadvantages
There are several disadvantages to parallel processing. The first is that it can be difficult to learn; programming that targets parallel architectures can be overwhelming at first, so it does take time to fully understand. Additional, code tweaking is not straightforward and must be modified for different target architectures to properly improve performance. It’s also hard to estimate consistent results because communication of results can be problematic for certain architectures. Finally, power consumption is a problem for those instituting a multitude of processors for various architectures; a variety of cooling technologies will be required in order cool the parallel clusters.
Where is it Used?
This type of programming can be used for everything from science and engineering to retail and research. It’s most common use from a societal perspective is in web search engines, applications, and multimedia technologies. Nearly every field in America uses this programming in some aspect, whether for research and development or for selling their wares on the web, making it an important part of computer science.
Parallel computing is the future of programming and is already paving the way to solving problems that concurrent programming consistently runs into. Although it has its advantages and disadvantages, it is one of the most consistent programming processes in use today. Now that there is an answer to the question of what is parallel programming, the next question should be, how can a professional use this type of programming in their field?
 venereology answered 8 months ago
venereology answered 8 months agoRelated Solutions
Describe three types of memory that are used in an MSP430, explain specifically what each memory...
What are the different types of application architectures?
List and describe briefly 3 Types of Option Strategies:
List and briefly describe four different types of firms in the intermediary channel. What are the...
Computer Architecture Theme: External Memory Very briefly discuss flash memory?
Identify modern architectures and recent trends in computer architecture. (Hints: Parallel and Distributed Approaches, Pipelining, Multi-cores,...
1) List the two major types of glands and describe the function of each type of...
1) There are several types of corporations, list the different types and what type would most...
1. Describe the purpose of some components in Internal Memory of a computer. 2. how Cache Memory...
Question 3. Describe memory types used in the MIPS assembly. Explain registers used in the MIPS...
- Need solution: HSL Company produces rugs. The following cost information from last year is available: Total...
- You are the network administrator for your organization. Your DHCP server (Server1) has a scope of...
- python3 Let x0,...,xn−1 be n numbers stored in the list x. The median of x, denoted...
- Raintree Cosmetic Company sells its products to customers on a credit basis. An adjusting entry for...
- 1. The larger the calculated χ2 value in a goodness-of-fit test, the _______ likely the data...
- tcp 16115
- #include <iostream> #include <fstream> #include <vector> #include <string> using namespace std; // Define a Person class,...