Question
In: Computer Science
def get_words(filename): ''' (str) -> list of str Given the name of a file which...
def get_words(filename):
'''
(str) -> list of str
Given the name of a file which contains many words
(one word per line), return a list of all these words.
The file may have comments and a blank space at the beginning
of the file, which should be ignored. All comment lines start
with
a semicolon ';'.
'''
Python
Solutions
Expert Solution
TEXTFILE Content :
;efsf
;gwe
privacy
pepper
abolish
desk
;hk
introduce
finish;
quarter
courage
fabricate
duck
amputate
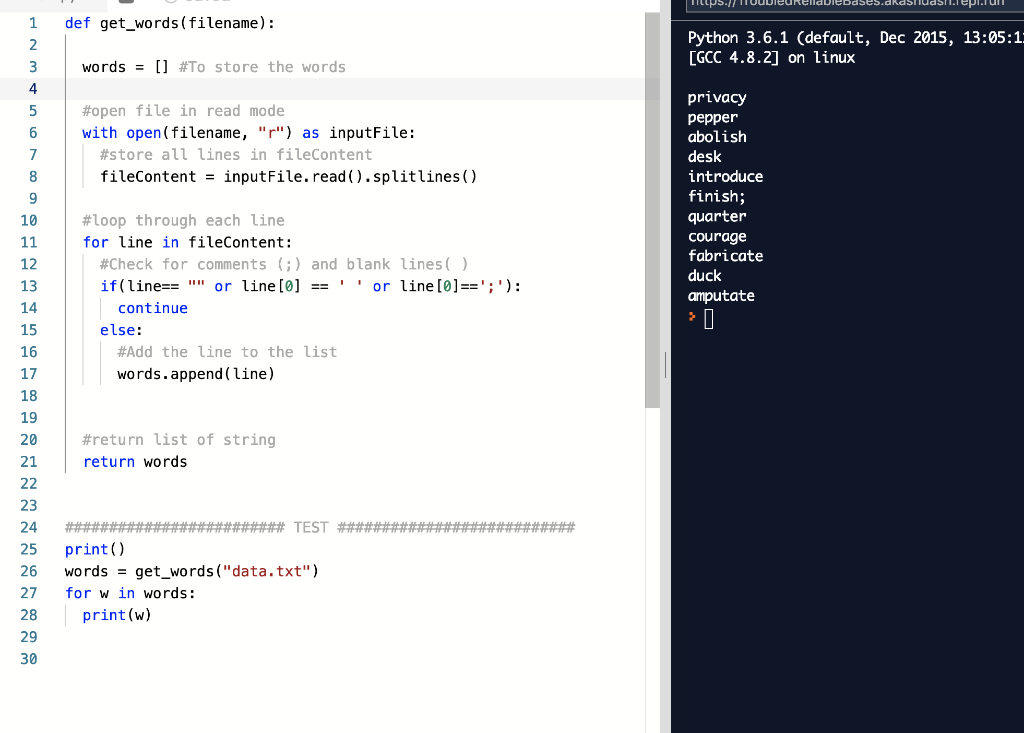
def get_words(filename):
words = [] #To store the words
#open file in read mode
with open(filename, "r") as inputFile:
#store all lines in fileContent
fileContent = inputFile.read().splitlines()
#loop through each line
for line in fileContent:
#Check for comments (;) and blank lines( )
if(line== "" or line[0] == ' ' or line[0]==';'):
continue
else:
#Add the line to the list
words.append(line)
#return list of string
return words
######################### TEST ###########################
print()
words = get_words("data.txt")
for w in words:
print(w)
 venereology answered 2 weeks ago
venereology answered 2 weeks agoRelated Solutions
A file name is supposed to be in the form filename , ext . Write a...
Python code def plot_dataset(file_path): """ Read in a text file where the path and filename is...
In Python write a function with prototype “def wordfreq(filename = "somefile.txt"):” that will read a given...
def compareRisk(compareCountry, countryList, filename): filename = open(filename, "r") content = filename.readlines() returnList =...
def warmer_year(temps_then: List[int], temps_now: List[int]) -> List[str]: """Return a list of strings representing whether this year's...
def read_words(filename, ignore='#'): """ Read a list of words ignoring any lines that start with the...
Given the python code below, show output: class MyClass: i = ["1010"] def f(self, name): self.i.append(str("470570"))...
In python def lambda_2(filename): # Complete this function to read grades from `filename` and map the...
Can you tell me what is wrong with this code ? def update_char_view(phrase: str, current_view: str,...
In python Complete the function get_Astring(filename) to read the file contents from filename (note that the...
- A rural 6-lane divided highway with AADT = 30,000 veh/ day, with composition [(80% PC –...
- *VISUAL BASIC* Construct and instantiate an array of strings called afcSouth that contains the following information...
- LAG network inc. balance sheet and income statement are as follows: LAG network inc. income statement...
- Calculate the pH at the equivalence point in titrating 0.110 M solutions of each of the...
- why joints differ in their degree of mobility.
- How do customers typically respond to service failures? When a service failure occurs, what can firms...
- Some discarded solid chemical waste dissolves slowly in a large drain pipe in which the water...