Question
In: Computer Science
What is clustering? Explain how K-Means Clustering Algorithm works? What are the Advantages and disadvantages of...
-
What is clustering? Explain how K-Means Clustering Algorithm works?
-
What are the Advantages and disadvantages of Clustering ALgorithms discussed in our class (K-Means,Hierchal)?
-
Which Clustering Algorithm is better K-Means or hierarchical Clustering? Explain with a proper example which is better algorithm?
Solutions
Expert Solution
What is clustering:
A cluster refers to a collection of data points aggregated
together because of certain similarities.
Data clustering approaches can group similar data into clusters.
The grouped Data will usually reveal important meanings.
Data that are close to each other tend to share some external
relationship. This relationship can be established to group the
data into clusters.
How K-Means Clustering Algorithm works:

- In k∗-means, we also use the random initialization method to choose k∗ starting centers, and first assign all points into k∗clusters.
- Then we get feature values of mean for each cluster,as shown in lines 1-3. Next, k∗-means performs hierarchical clustering along with k-means adjusting iteration in lines 4-22 and nearest clusters associated with top-n distances merging in line 23-25.
- Line 6 describe the proposed cluster pruning strategy. We use collections CS to store the neighbor clusters of specific cluster which after prune remote clusters by Lemma 2.
- Then, we only need to verify the adjustable clusters in search space of CS for each point in Ci.
- Once percentage of moved points is lower than given θ in first round k-means optimized update principle will be started and radius will be updated during this process( lines 7- 14).
- For algorithm’s efficiency, we
maintain a value r in each cluster to update its radius( lines
9-13). At the end of each iteration, each cluster mean m and it’s
radius is replaced by
 ,
, directly.Lines 23-25 show top-n nearest clusters merging which
reduce number of clusters from
directly.Lines 23-25 show top-n nearest clusters merging which
reduce number of clusters from 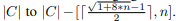
- Therefore, parameter n is not fixed, but ranges from given n to 1. For each round refining of k∗-means, we use a decrease strategy to determine value of n, and a top-1 may be performed at final round to make number of clusters reach at k.
 ,
, directly.Lines 23-25 show top-n nearest clusters merging which
reduce number of clusters from
directly.Lines 23-25 show top-n nearest clusters merging which
reduce number of clusters from 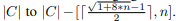
----------------------------------------------------------------------------------------------------------------------
 venereology answered 1 year ago
venereology answered 1 year agoRelated Solutions
In MATLAB, Implement a hybrid clustering algorithm which combines hierarchical clustering and k-means clustering.
Question: In MATLAB, Implement a hybrid clustering algorithm which combines hierarchical clustering and k-means clustering. The...
INTRODUCTION TO DATA MINING Question 3: K-means clustering Use the k-means algorithm and Euclidean distance to...
Why do business from clusters and what are the advantages or disadvantages of clustering?
K-means clustering: a. In the k-means lab, you examined different values for k using the "knee"...
Suppose you have been building a model using the k-means clustering algorithm and you keep finding...
Question 1. What is k-means clustering? How does it work? Give a few examples that you...
What are the advantages and disadvantages of share options as means of executive compensation?
One way to cluster objects is called k-means clustering. The goal is to find k different...
Summarize the advantages and disadvantages of mergers and acquisitions as a means of diversification. Discuss how...
- On January 1, 2018, bonds with a face value of $ 79,000 were sold. The bonds...
- How do I make this sort in true alphabetical order instead of ascii(ABCabc) order? I am...
- As a healthcare provider in physical therapy, athletic training, or as an exercise scientist and personal...
- in the market for makeup artists, what happens after the invention of high-definition tv allowing viewers...
- 10. What are the three monetary policy tools of the Fed? Briefly describe how each tool...
- In what ways would the role of a manager working in a nonstandard international assignment arrangement...
- Write a Bash script called move that could replace the UNIX command mv. 'move' tries to...