Questions
I need to, Modify my mapper to count the number of occurrences of each character (including punctuation...
I need to, Modify my mapper to count the number of occurrences of each character (including punctuation marks) in the file.
Code below:
#!/usr/bin/env python
#the above just indicates to use python to intepret this file
#This mapper code will input a line of text and output <word, 1> #
import sys
sys.path.append('.')
for line in sys.stdin:
line = line.strip() #trim spaces from beginning and end
keys = line.split() #split line by space
for key in keys:
value = 1
print ("%s\t%d" % (key,value)) #for each word generate 'word TAB 1' line
In: Computer Science
1. A _______ is a long-term debt instrument that promises to pay interest periodically as well...
1. A _______ is a long-term debt instrument that promises to pay interest periodically as well as a principal amount at maturity to the investor. (answer is one word, four letters)
2. The rate used to determine the amount of cash the investor receives is the ______ rate. (answer is one word, six letters)
3. The interest rate bond investors expect for their investment is the ______ i rate of interest. (answer is one word, six letters)
4. A company issues 10% bonds at a time when other bonds of similar risk are paying 12%. These bonds will sell at a ________________. (one word, eight letters)
5. A company issues 10% bonds at a time when other bonds of similar risk are paying 8%. These bonds will sell at a ________________. (one word, seven letters)
6. Payment for the use of money is (one word, 8 letters)
7. A series of equal dollar amounts to be paid or received at evenly spaced time intervals is a (or an)
-discount
-future value
-present value
-annuity
8. For a single payment: what is the present value factor for four periods at a discount rate of 11%?
9. For a single payment: what is the present value factor for sixteen periods at a discount rate of 10%?
10. For a single payment: what is the present value factor for one period at a discount rate of 10%?
11. For an annuity: what is the present value factor for nine periods at a discount rate of 12%?
12.For an annuity: what is the present value factor for twenty periods at a discount rate of 8%?
13. For an annuity: what is the present value factor for five periods at a discount rate of 8%?
In: Accounting
Use python write a function that translates the input string into Pig Latin. The translation should...
Use python write a function that translates the input string into Pig Latin. The translation should be done word by word, where all words will be separated by only one space. You may assume that each word must have at least one vowel (a,e,i,o,u and uppercased counterparts), and there will be no punctuation or other special characters in the input string.
The Pig Latin rules are as follows:
-
For words that begin with consonants, all letters before the initial vowel are placed at the end of the word sequence. Then, “ay” is added.
Example: “pig” -> “igpay”, “banana” -> “ananabay”, “duck” -> “uckday”,
“stupid” -> “upidstay”, “floor” -> “oorflay”, “string” -> “ingstray”.
-
For words that begin with vowels, append “yay” to the end of this word.
Example: “omelet” -> “omeletyay”, “eat” -> “eatyay”, “egg” -> “eggyay”.
-
For whatever reason, we are afraid of 8-letter words. Thus, whenever you encounter a word with 8 letters, you should stop translating immediately and return what we have translated so far.
Example: “A short sentence” -> “Ayay ortshay”
-
Hint: command in might be useful here
-
Hint: either break or continue may be helpful here. Think which one
-
Hint: the method enumerate() can be useful. A brief explanation and examples of its potential use can be found here.
def pig_latin(string):
"""
>>> pig_latin('Hi how are you')
'iHay owhay areyay ouyay'
>>> pig_latin('Absolute')
''
>>> pig_latin('When words begin with consonant clusters')
'enWhay ordsway eginbay ithway onsonantcay'
"""
In: Computer Science
A developmental psychologist believes that word chunking impacts vocabulary development. To investigate, the psychologist assesses a...
A developmental psychologist believes that word chunking impacts
vocabulary development. To investigate, the psychologist assesses a
group of 6-year olds by asking them to recall as many words as they
can starting with the letter "v". The psychologist then asks the
parents to ensure their children practice word chunking for 60
minutes each day for four weeks. At the end of the four weeks, the
psychologist assesses the same children by asking them to recall as
many words starting with the letter "v" again. What can be
concluded with α = 0.10? The word recall data are below.
| 1nd | 2nd |
| 6 8 9 5 9 6 4 7 |
5 |
c) Obtain/compute the appropriate values to
make a decision about H0.
(Hint: Make sure to write down the null and alternative hypotheses
to help solve the problem.)
critical value = ; test statistic =
Decision: ---Select--- Reject H0 Fail to reject H0
d) If appropriate, compute the CI. If not
appropriate, input "na" for both spaces below.
[ , ]
e) Compute the corresponding effect size(s) and
indicate magnitude(s).
If not appropriate, input and/or select "na" below.
d = ______ ; ---Select--- na trivial effect
small effect medium effect large effect
r2 = ______ ; ---Select--- na
trivial effect small effect medium effect large effect
f) Make an interpretation based on the
results.
Word chunking significantly impairs vocabulary development.
Word chunking significantly improves vocabulary development.
Word chunking did not have a significant impact on vocabulary development.
In: Statistics and Probability
Instructions: Type your answer using the Micro soft word, Line spacing should be 1.5 space line...
In: Mechanical Engineering
Refer to Data
Refer to Data Set 8 in Appendix B and use the word counts measured for men and women from the couples listed in the first two columns of Data Set 8. Find the best predicted word count of a woman given that her male partner speaks 6000 words in a day.
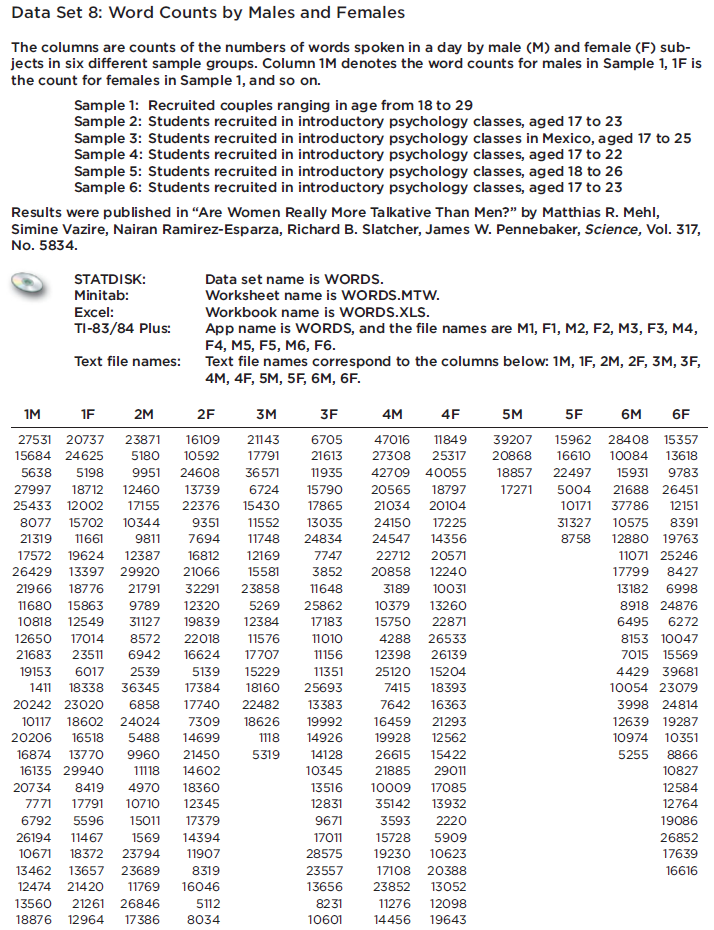
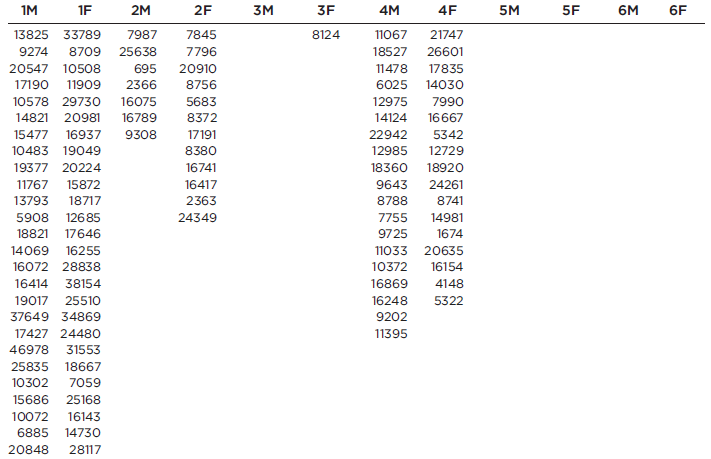
In: Statistics and Probability
Select 5 words to summarize what you have learned so far about God, Jesus, the Gospel,...
Select 5 words to summarize what you have learned so far about God, Jesus, the Gospel, and the Bible. Take each word and write 2 sentences each explaining why you selected that particular word and how it summarizes what you've learned so far.
In: Psychology
: This exercise will give you a review of Strings and String processing. Create a class...
: This exercise will give you a review of Strings and String processing. Create a class called MyString that has one String called word as its attribute and the following methods: Constructor that accepts a String argument and sets the attribute. Method permute that returns a permuted version of word. For this method, exchange random pairs of letters in the String. To get a good permutation, if the length of the String is n, then perform 2n swaps. Use this in an application called Jumble that prompts the user for a word and the required number of jumbled versions and prints the jumbled words. For example, Enter the word: mixed Enter the number of jumbled versions required: 10 xdmei eidmx miexd emdxi idexm demix xdemi ixdme eximd xemdi xdeim Notes: 1. It is tricky to swap two characters in a String. One way to accomplish this is to convert your String into an array of characters, swapping the characters in the array, converting it back to a String and returning it. char[] chars = word.toCharArray(); will convert a String word to a char array chars. String result = new String(chars); converts a char array chars into a String. p 6 2. Use Math.random to generate random numbers. (int)(n*Math.random()) generates a random number between 0 and n-1. java
In: Computer Science
C++ Programming The following program reads the sentences in "fdata.txt" and stores each word in a...
In: Computer Science
I'm Getting an "unindented error" Please fix the bolded codes. Because I don't know whats going...
I'm Getting an "unindented error" Please fix the bolded codes. Because I don't know whats going on. Thank You.
# This program exercises lists.
# The following files must be in the same folder:
# abstractcollection.py
# abstractlist.py
# arraylist.py
# arrays.py
# linkedlist.py
# node.py
# input.txt - the input text file.
# Input: input.txt
# This file must be in the same folder.
# To keep things simple:
# This file contains no punctuation.
# This file contains only lowercase characters.
# Output: output.txt
# This file will be created in the same folder.
# All articles are removed.
# Certain prepositions are removed.
# Duplicate consecutive words are reduced to a single
occurrence.
# Note: The words "first" and "last" are not reduced.
# Certain misspelled words are flagged.
# Occurrences of "first" are moved to the front of a line.
# Occurrences of "last" are moved to the end of a line.
from arraylist import ArrayList
from linkedlist import LinkedList
# Data:
articles = ArrayList(["a", "the"])
prepositions = LinkedList(["after", "before", "from", "in", "off",
"on", "under", "out", "over", "to"])
misspellings = ["foriegn", "excede", "judgement", "occurrance",
"preceed", "rythm", "thier", ]
inputFile = open("input.txt", "r")
outputFile = open("output.txt", "w")
FIRST = "first"
FLAG = "FLAG:"
LAST = "last"
# Processing:
# Part 1:
# Removes all items from the words list that are found in the
removals list.
# Input:
# words - an ArrayList of words, no uppercase, no punctuation
# wordsIter - a list iterator for the words list
# removals - the list of words to remove
def removeItems(words, wordsIter, removals):
wordsIter.first()
while(words.hasNext()):
word = words.next()
if word in removals:
wordsIter.remove()
# Part 2:
# Removes extra occurrances of consecutive duplicate words from the
words list.
# Note: It does not reduce the words "first" and "last".
# Input:
# words - an ArrayList of words, no uppercase, no punctuation
# wordsIter - a list iterator for the words list
def reduceDuplicates(words, wordsIter):
previousWord=""
wordsIter.first()
while(words.hasNext()):
word=words.next()
if(word=="first" or word=="last"):
previousWord=word
continue
if(word==previousWord):
wordsIter.remove()
previousWord=word
# Part 3:
# Flags certain misspelled words in the words list by inserting
"FLAG:" before them.
# Input:
# words - an ArrayList of words, no uppercase, no punctuation
# wordsIter - a list iterator for the words list
# misspellings - the list of misspelled words to flag
def flagMisspelled(words, wordsIter, misspellings):
wordsIter.first()
while(wordsIter.hasNext()):
word=words.next()
if word in misspellings:
wordsIter.insert(FLAG)
wordsIter.next()
# Part 4:
# Move all occurrences of "first" to the front of the words
list.
# Input:
# words - an ArrayList of words, no uppercase, no punctuation
# wordsIter - a list iterator for the words list
def moveFirstLit(words, wordsIter):
countFirst = 0
wordsIter.first()
while (wordsIter.hasNext()):
word = wordsIter.next()
if (word == FIRST):
wordsIter.remove()
countFirst += 1
for count in range(countFirst):
wordsIter.first()
if (wordsIter.hasNext()):
wordsIter.next()
wordsIter.insert(FIRST)
# Part 5:
# Move all occurrences of "last" to the end of the words
list.
# Input:
# words - an ArrayList of words, no uppercase, no punctuation
# wordsIter - a list iterator for the words list
def moveLastLit(words, wordsIter):
countLast = 0
wordsIter.last()
while (wordsIter.hasNext()):
word = wordsIter.next()
if (word == LAST):
wordsIter.remove()
countLast += 1
for count in range(countLast):
wordsIter.last()
if (wordsIter.hasNext()):
wordsIter.next()
wordsIter.insert(LAST)
def writeOutputLine(words):
outputLine = " ".join(words)
outputLine = outputLine + "\n"
print(outputLine, end="")
outputFile.write(outputLine)
# Main processing loop:
for line in inputFile:
words = ArrayList(line.split())
wordsIter = words.listIterator()
# Make no changes to blank lines:
if (len(words) == 0):
writeOutputLine(words)
continue
# Make no changes to comment lines:
if (words[0] == "#"):
writeOutputLine(words)
continue
# Remove articles:
removeItems(words, wordsIter, articles)
# Remove prepositions:
removeItems(words, wordsIter, prepositions)
# Reduce duplicate consecutive words to a single
occurrence:
reduceDuplicates(words, wordsIter)
# Insert "FLAG:" before certain misspelled words:
flagMisspelled(words, wordsIter, misspellings)
# Move all occurrences of "first" to the front of the line:
moveFirstLit(words, wordsIter)
# Move all occurrences of "last" to the end of the line:
moveLastLit(words, wordsIter)
# Write output line:
writeOutputLine(words)
# Wrap-up
inputFile.close()
outputFile.close()
In: Computer Science